Des solutions pour les conflits au niveau de la base de données pour les tests exécutés en parallèle
On m’a demandé il y a quelques jours si j’avais des ressources parlant de solution aux conflits entre tests joués en parallèle lorsqu’ils touchent à la base de données. J’avais quelques pistes à partager et je me suis dit que ça ferait un bon sujet d’article. Le voici donc.
Le problème
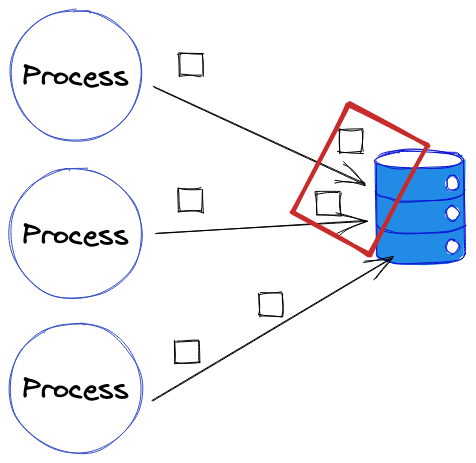
Lorsque l’on joue des tests en parallèle on se retrouve face à des problèmes qui n’existaient pas lorsque les tests étaient joués en série, notamment lorsque les tests partagent une ressource, comme une base de données.
Des tests qui, jusque-là, tournaient de manière régulière et avaient le même comportement à chaque fois qu’ils étaient exécutés commencent à avoir des comportements différents d’un run de test à un autre, parfois ils passent, parfois ils échouent. On parle de flaky tests pour décrire les tests qui vont passer ou échouer en fonction de certaines conditions.
Prenons un exemple avec la base de données :
- Nous avons deux tests qui ajoutent un utilisateur dans la base de données lorsqu’ils sont lancés.
- Bien sûr, le nom de l’utilisateur doit être unique.
- Les choses sont bien faites et après chaque test l’utilisateur est supprimé de la base de données, ce qui permet aux différents tests d’utiliser le même nom d’utilisateur.
Ces tests vont fonctionner parfaitement en série. En revanche en parallèle il est possible que l’un d’eux échoue s’il essaye d’ajouter l’utilisateur à la base de données avant que l’autre test n’ait eu le temps de faire le ménage.
Nos deux tests qui étaient, jusque-là, reproductibles deviennent flaky.
Il existe, bien évidemment, plusieurs solutions à ce problème.
Bien préparer les données
Commençons par la fausse bonne idée.
Une solution est de faire en sorte de préparer les jeux de données qui vont être utilisés dans les tests pour éviter les collisions. Cette solution semble simple à première vue mais risque de poser des problèmes de maintenance des tests sur le long terme.
Il va falloir s’assurer que certaines données ne sont utilisées qu’une seule fois et devenir imaginatif pour créer de nouvelles données.
On peut imaginer mettre en place des outils qui permettent de connaitre quelles sont les données déjà utilisées pour ne pas s’en resservir, mais ces outils risquent de devenir complexes assez vite. Il ne s’agit là, à mon avis, que d’une fuite en avant.
On peut également se dire que l’on peut lancer les tests pour savoir si chaque nouveau test n’entre pas en conflit avec un test précédent mais malheureusement il est possible que le conflit ne soit pas détectable immédiatement et le devienne plus tard.
Bref, cette option est donc clairement à déconseiller.
Faire tourner les tests en séries
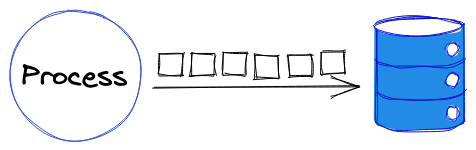
Cette solution peut sembler décevante mais a le mérite d’exister : Si les tests n’étaient pas flaky lorsqu’ils tournaient en séquence une solution est d’abandonner la parallélisation.
Dans cette solution on échange du temps d’exécution contre davantage de fiabilité. Si le temps d’exécution sans la parallélisation n’est pas trop important il s’agit sans doute de la solution la plus simple.
Mais lorsque l’on met en place de la parallélisation c’est parce que la durée d’exécution des tests était trop importante et que l’on veut aller plus vite.[1]
Ce qui fait que cette solution risque de ne pas satisfaire tout le monde et nous mène l’option suivante.
Se passer de la base de données
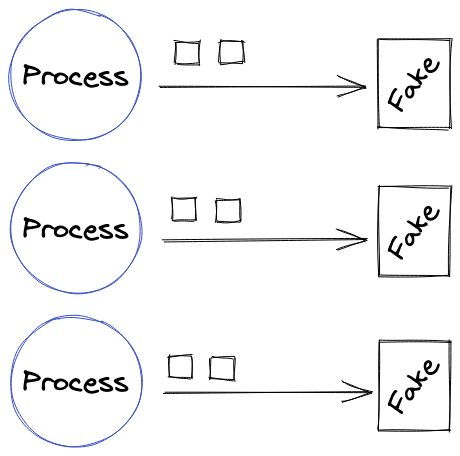
Puisque le problème vient du partage de la base de données entre plusieurs tests une autre solution est de se passer de la base de données pour les tests. On peut imaginer remplacer les différentes dépendances qui s’appuient sur une base de données par des doublures qui vont avoir le même comportement que la dépendance originale mais ne vont pas avoir besoin de partager de ressource.
Autrement dit il est possible d’utiliser un fake par processus, tel qu’un repository en mémoire, qui va stocker les données dans un tableau. Une instance de ce repository sera créée dans chaque processus, ou même mieux pour chaque test, ce qui va éviter les conflits entre les tests.
Mais là encore cette solution a quelques inconvénients, le premier étant que l’on aura toujours besoin de tests avec la base de données pour s’assurer que l’intégration de notre code avec celle-ci se passe comme voulu (via des tests end-2-end, des tests de contrat qui s’assurent que notre doublure a bien le même comportement que la dépendance remplacée, ou autre...). Ces tests peuvent eux aussi potentiellement rencontrer des problèmes lorsqu’ils sont exécutés en parallèle. Retour à la case départ en quelque sorte.
Sauf que tout n’est pas perdu : si l’on a réussi à réduire le nombre de tests qui dépendent de la base de données il y a des chances que notre suite de tests tourne beaucoup plus rapidement et l’on peut alors faire tourner nos tests en séries. L’option précédente devient viable.
Le second inconvénient est la potentielle difficulté de mise en place de cette solution. Transformer l’architecture d’une application pour permettre de pouvoir remplacer certaines dépendances pendant les tests n’est pas forcément facile et peut prendre beaucoup de temps. C’est pourquoi il peut s’agir de la solution la plus compliquée à mettre en œuvre suivant l’état du système.
Utiliser des transactions
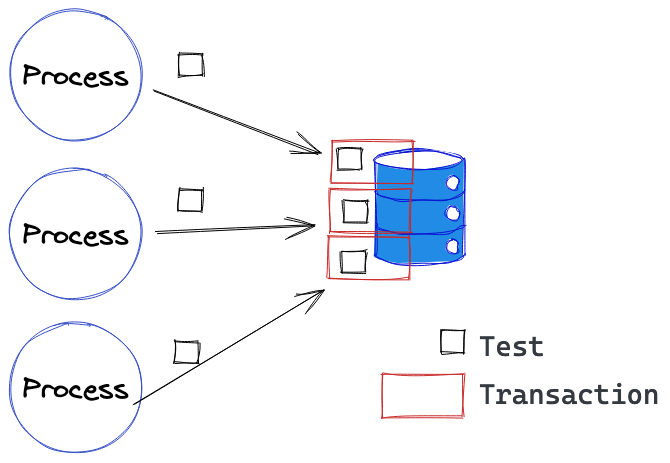
Fort heureusement il y a une solution généralement plus rapide à mettre en place : démarrer une transaction avant le début du test et faire un rollback une fois le test terminé, que ce soit un succès ou non. Chaque test est alors exécuté dans son bac à sable, sur la même base de données, et ne peut pas interagir avec les autres.
Dans le monde PHP la plupart des frameworks proposent une solution pour ça, soit nativement, soit via des dépendances à installer[2]. Il est également possible de faire sa propre implémentation.[3] Cette solution nécessite en général beaucoup moins de travail pour pouvoir être mise en place que la précédente.
Au passage, cette solution permet d’ailleurs de régler des problèmes d’interactions entre tests également lorsqu’ils sont lancés en série, sans avoir besoin de se préoccuper du nettoyage d’après test.
Évidemment, vous vous en doutez bien, cette solution a, elle aussi, un inconvénient. Pour fonctionner il faut que le test et le système sous test partagent la même connexion à la base de données. Si ce n’est pas le cas le test n’est pas en mesure démarrer et d’annuler la transaction. En fonction de l’architecture de l’application, il peut être compliqué de réussir à mettre la main sur la même connexion aussi bien dans le code de production que dans les tests. De plus, cette contrainte rend cette solution inefficace pour certains types de tests qui vont nécessairement devoir séparer le processus dans lequel tournent les tests du processus dans lequel tourne l’application - les tests end-2-end par exemple.
Heureusement, il reste encore une alternative...
Utiliser une DB par processus
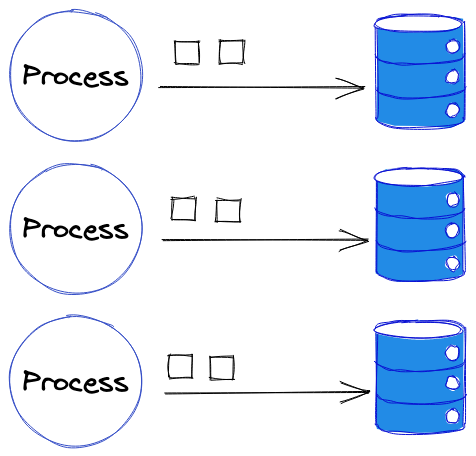
La dernière solution permet de répondre à la contrainte des processus différents entre le test et l’application, et également à toutes situations dans lesquelles on ne peut pas, ou l’on ne veut pas, mettre en place le système de transaction.
Plutôt que d’essayer de faire interagir les tests des différents processus avec la même base de données on va dédier une base de données à chacun.
En fonction du runner de test la mise en place peut-être plus ou moins compliquée.
Certains runners créent un identifiant incrémental pour chaque processus et donnent accès à cet identifiant via une variable d’environnement.[4]
Il est alors possible d’utiliser la variable d’environnement pour créer la connexion à la base de données dédiée au processus courant.
D’autres runners de test ne semblent pas fournir de variable d’environnement[5]. Il faut alors générer un identifiant unique dans un hook du runner de test qui va s’exécuter avant le début de tests et l’ajouter aux variables d’environnement. Et enfin, de la même manière, utiliser la variable d’environnement pour se connecter à la base de données.
Reste encore à créer les bases de données. Dans le cas de la variable d’environnement incrémentée il est possible de créer les différentes bases avant le début des tests pour peu que l’on connaisse le nombre de processus qui vont tourner en parallèle. C’est la solution simple.
Alternativement, si l’identifiant est aléatoire ou que le nombre de processus ne peut être connu apriori, il est possible de créer la base de données avant l’exécution des tests, là encore dans un hook. Particulièrement dans le cas d’un identifiant aléatoire, il faut penser à supprimer la base de données qui vient d’être créée à la fin des tests pour éviter de faire une collection de bases inutilisées.[6]
À noter qu’il est possible que cette solution soit plus rapide à mettre en place que la solution avec les transactions selon l’état du système. Une fois le système de création de bases de données installé il n’y a pas besoin de faire de nombreux changements. Il faut uniquement modifier la création de la connexion pour indiquer la base de données à utiliser.
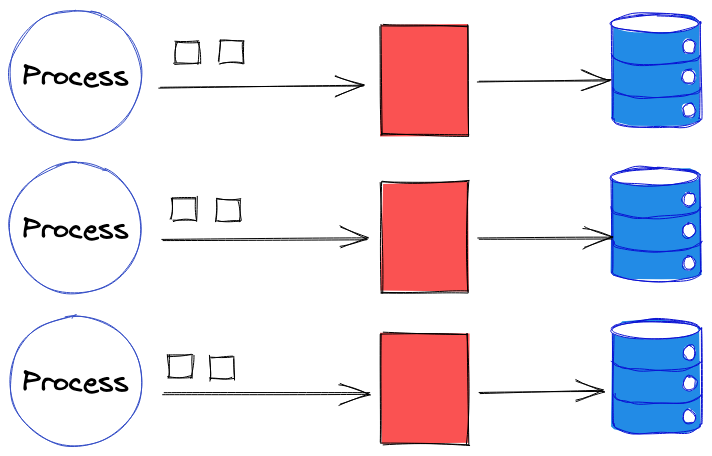
Dans le cas des tests end-2-end l’idée va rester la même, une base de données par processus de tests, mais la mise en pratique va devoir être un peu différente. Il va falloir permettre aux tests d’indiquer à quelle base de données ils sont rattachés. Cela peut se faire en utilisant plusieurs instances de l’application, chacune connectée à une base de données différentes. Chaque processus de test va alors pouvoir appeler l’instance qui lui est dédiée (ex.: en changeant de nom de domaine ou de port).
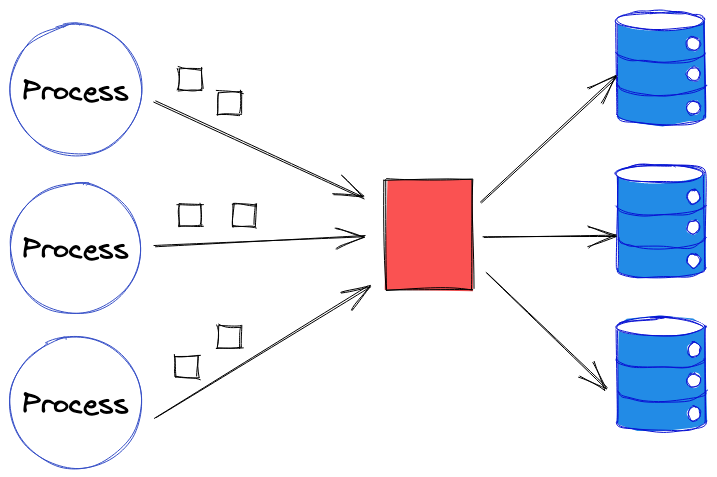
Une autre solution, s’il n’est pas possible d’avoir plusieurs instances de l’application, est que le test communique le nom de la base de données à laquelle il souhaite s’adresser (ex.: au travers d’un header) à celle-ci, et qu’en fonction de l’information transmise elle se connecte à la base de données. Là encore cette solution présente des inconvénients, principalement liés à la mise en place de logique dédiée spécialement aux tests pour pouvoir changer de base de données.
Conclusion
Comme souvent, il n’y a pas une seule solution qui va convenir à toutes les situations. Avec cet article, on a vu différentes pistes de solutions, qui peuvent répondre à différents cas d’usage, et qui sont plus ou moins faciles à mettre en place selon l’état de l’application.
Et donc comme toujours, pas de solution miracle, c’est à vous de voir laquelle de ces options s’applique le mieux à votre contexte.
Il existe peut-être d’autres solutions à ce type de problème. Si vous en connaissez n’hésitez pas à me contacter ici ou sur Twitter.
Et si vous voulez faire en sorte d'avoir des tests avec lesquels vous prendrez un réel plaisir à travailler, vous pouvez accéder à ma formation vidéo sur l'amélioration des tests automatisés. Il vous est aussi possible de prendre un rendez-vous pour que nous travaillions ensemble à faire passer votre équipe au niveau supérieur.
Certainement pas pour tester, pour le fun, ou simplement parce que l’outil le permet. Non, non... ↩︎
Par exemple Laravel l’inclut nativement, côté Symfony il faut installer un plug-in pour Doctrine. ↩︎
Voici un exemple d’implémentation en PHP avec PhpUnit et PDO qui n’est pas de toute beauté, mais qui donne une idée de ce qui peut être fait avec une "encapsulation" de la connexion et une extension PhpUnit. ↩︎
C’est le cas de Paratest côté PHP, et de Jest dans le monde JS. ↩︎
xUnit, côté .Net ne semble pas partager de variable d’environnement avec un ID pour le processus. Cette série d’articles donne une solution en C# avec Entity Framework. ↩︎
Un exemple de hook qui permet de créer et de supprimer une base de données avec un nom aléatoire en PHP. ↩︎
- Améliorez vos tests automatisés : Vous apprendrez comment transformez vos tests pénibles qui vous perdre votre temps en tests qui vous en font gagner. Il s'agit d'un cours en vidéo en français, à votre rythme.
- Aider vos équipes: J'ai des équipes à délivrer du meilleur logiciel plus rapidement. Ensemble, nous travaillerons sur les problèmes techniques, aussi bien au niveau du code, des tests ou de l'architecture, ou nous verrons comment modifier votre manière de travailler et votre organisation pour obtenir de meilleurs résultats, cela en fonction de vos besoins. Prenez un rendez-vous gratuit pour discuter de votre situation et que l'on voit ensemble comment je pourrais vous aider.
- Faire une présentation dans votre organisation: J'aime parler de certains sujets, et je peux venir le faire dans votre organisation (meetup, conference, entreprise, BBL). Si vous pensez que l'on peut préparer un sujet ensemble, discutons-en !
